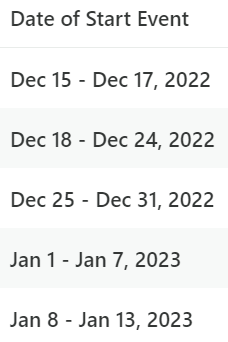
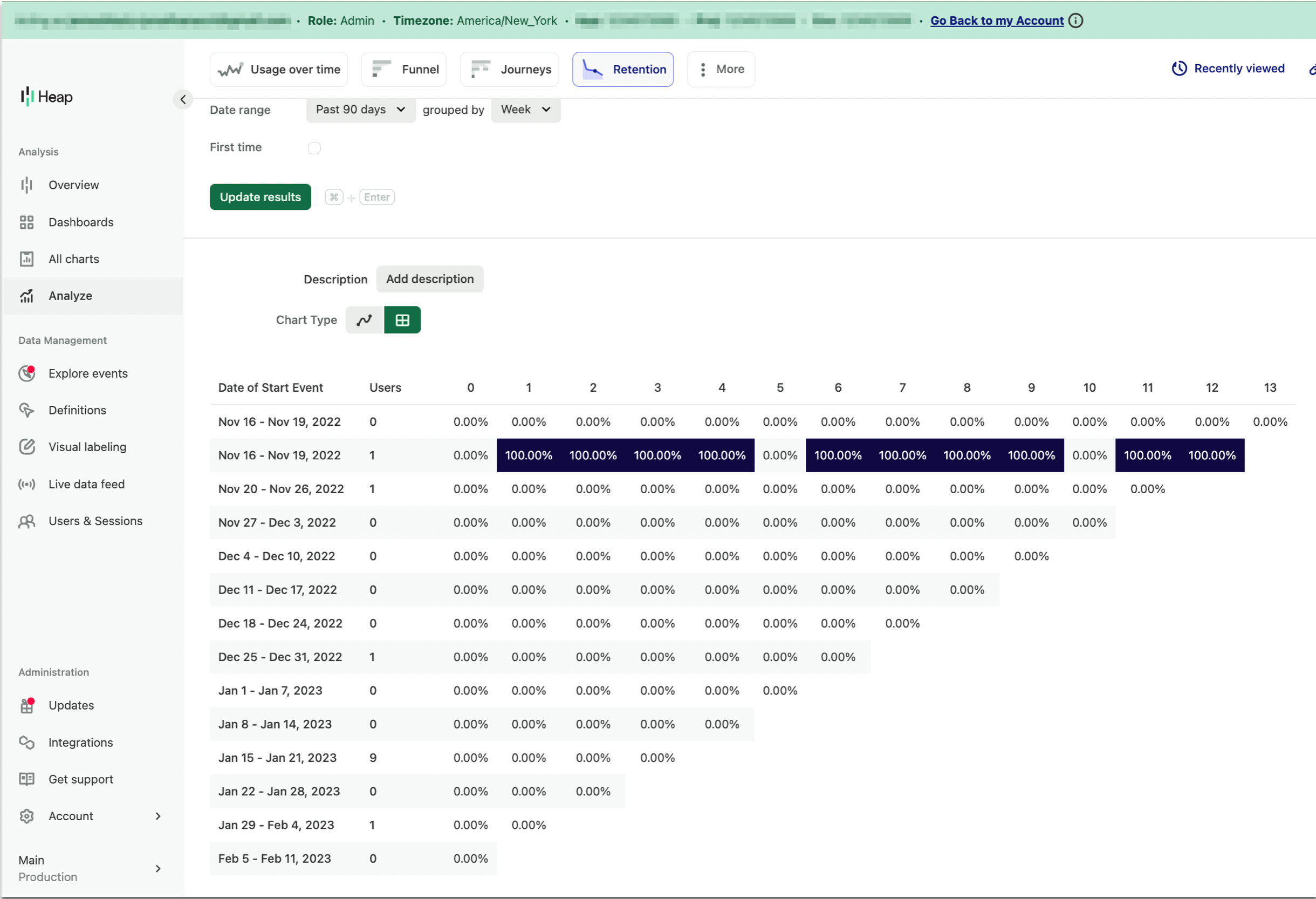
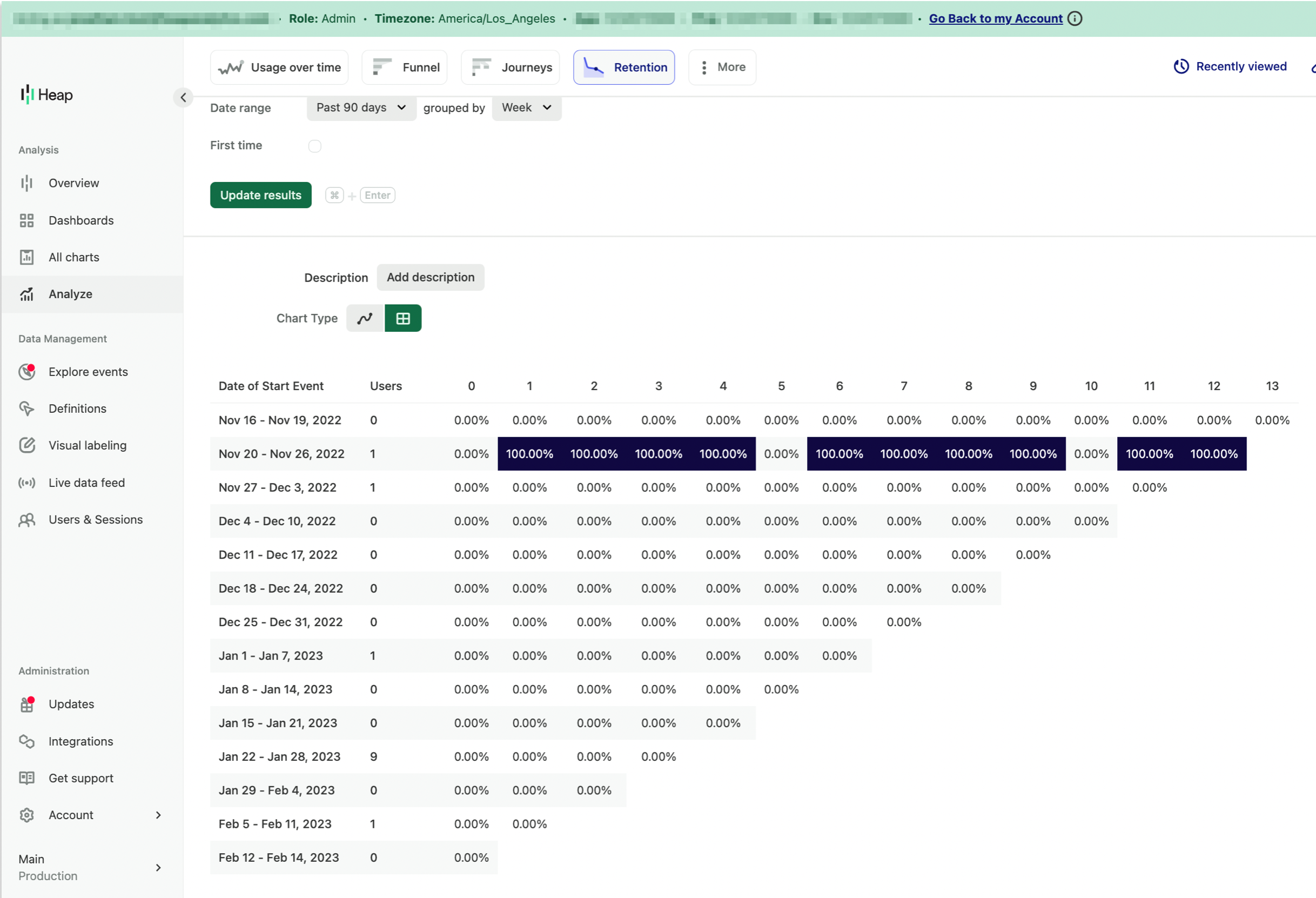
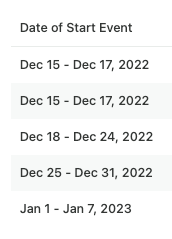
I am creating a retention analysis chart, grouped by the week of the start event and then also grouped by week over the past 30 days. Why are there two first weeks (ie Dec 15 - 17, 2022)? Noting that both of these “weeks” have different user counts.
Best answer by anthony
View original